原文
Hot-Cold Storage Separation in Practice — weiihann (2026-06-08)
ホット・コールドストレージ分離の実践
EIP-8188は、すべてのアカウントとストレージスロットにコンセンサス層から見えるタイムスタンプを追加し、それぞれが最後に変更された時刻を記録します。その価格設定ルールでは、このフィールドを使用して書き込みが非アクティブな状態への書き込みにより多くの料金を課しますが、ここで重要なのはフィールド自体です。これにより、すべてのクライアントが、どの状態が最近変更された(ホット)で、どの状態が長期間変更されていない(コールド)かについて同じシグナルを得られるからです。このEIPは、意図的にストレージアーキテクチャを義務付けていません。クライアントにメタデータを提供するだけで、その使い方については自由に残しています。
この文書では、そのシグナルを利用してクライアントができることの一つを測定します。それは、コールドステートをホットステートから物理的に分離し、より小さなホットなワーキングセットをメインデータベースに保持し、コールドな残りを安価なフラットファイルに格納することです。問題は、実際のノードでどれだけのディスク容量が実際に節約されるのか、そしてどの分離方法が優れているのかということです。
メインネットのgo-ethereum (geth) ノードで3段階の実験を行い、「コールド」ステートをホットデータベースから引き出すことでどれだけのディスク容量が節約されるかを確認しました。ここでは、各ステップが何を行い、何を実際に測定したかを記述します。
3つのステップ:
- ベースライン。 通常のgethノード。
- 期間の注入。 すべてのアカウントとスロットに、最後に使用された期間をタグ付けし、何がコールドであるかを判別できるようにする。
- 非アクティブな状態の移動。 コールドな部分をメインデータベースからフラットファイルに引き出し、ノードがホットに保つ必要があるものを縮小する。
以下のすべての測定は、ブロック19,999,256のメインネットの1つのデータディレクトリで行われました。
gethが状態を保存する方法
状態とは、すべてのアカウント(残高、ナンス、コード、ストレージルート)と、すべてのコントラクトのストレージスロットです。gethはこれらをキーバリューストア(PebbleDB)内に2回保持しています。
1. マークル・パトリシア・トライ (MPT)。 ルートハッシュがブロックのステートルートである認証済みツリーです。
アカウントトライ (ルートハッシュ = stateRoot)
|
(ブランチ)
/ \
(拡張) (ブランチ)
| / \
(ブランチ) (リーフ) (リーフ)
/ \
(リーフ) (リーフ)
すべてのコントラクトアカウントのストレージは、同じ形状の独自のトライです。
2. スナップショット。 リーフのみのフラットなキーと値のコピーで、読み取り時にツリーを辿る必要がありません。
accountHash -> account
accountHash + slotHash -> slot value
ステップ1:ベースライン
ブロック19,999,256のノード。サイズは特に記載がない限り論理バイト(レコード内容の合計)です。物理的なディスク上の圧縮されたPebbleDBは約251.75 GBです。
| コンポーネント | カウント | サイズ |
|---|---|---|
| トライノード(アカウント) | 334.7 M | 38.81 GB |
| トライノード(ストレージ) | 1,560.7 M | 109.33 GB |
| トライ合計 | 1,895.4 Mノード | 148.13 GB |
| スナップショット、アカウント(キー / 値) | - | 7.58 / 3.77 GB |
| スナップショット、ストレージ(キー / 値) | - | 69.74 / 13.32 GB |
| スナップショット合計 | 約1.15 Bレコード | 101.38 GB |
ステップ2:期間の注入
各アカウントとストレージスロットについて、最後に書き込まれた最新の期間を保存します。これはスナップショットのみに入ります。「期間」は単なる時間枠であり、ここでは1,314,000ブロック(約6ヶ月)です。リーフは、minAge期間(ここでは2なので、合計1年間の非アクティブ期間)以上書き込まれていない場合、非アクティブと見なされます。
この実験では、Xatuを主要なデータソースとして使用しました。
アクセス履歴ソース インジェクター スナップショット (ペブル)
+---------------------+ (キー, ブロック) +-------------+ 読み取り -> 期間設定 -> 書き込み
| アドレスAがブロックで書き込み | --------------> | 期間 = | +---------------------------+
| スロットSがブロックで書き込み | | (ブロック - フォーク)| ->| accountHash -> [acct, P] |
| ... | | / 期間長 | | slotHash -> [value, P] |
+---------------------+ +-------------+ +---------------------------+
(期間は常に上昇するのみ)
ComputePeriod(block) = (block - forkBlock) / blocksPerPeriod。forkBlockが17,371,256、blocksPerPeriodが1,314,000の場合、ヘッドは期間2に位置します。更新は常にレコードの期間を上昇させるだけなので、ソースは任意の順序で、バッチで、再試行を伴って差分を出力できます。
保存方法と、ほとんどコストがかからない理由。 期間はオプションの末尾RLPフィールドです。それが0の場合(追跡範囲内でレコードが一度も書き込まれていない場合)、バイトはレガシーレコードと同一であるため、最近書き込まれたレコードのみが大きくなります。
アカウントレコード:
前: RLP[ nonce, balance, storageRoot, codeHash ]
後: RLP[ nonce, balance, storageRoot, codeHash, period ] (+1から2バイト)
ストレージスロットレコード:
前: RLP("value") プレーンな文字列
後: RLP[ "value", period ] 2アイテムのリスト (+2から3バイト)
コスト(ステップ1からステップ2)。
| トライ | スナップショット | |
|---|---|---|
| 変更 | なし、バイト同一 | +0.2から0.3 GB(約32.5 Mアカウントと最近書き込まれたスロットで) |
| 割合 | 0% | 101 GBのスナップショットの0.5%未満 |
ステップ3:非アクティブな状態を移動する
すべてのリーフが最終使用期間(ステップ2)を保持するようになったので、状態のコールドな部分をメインデータベースからフラットファイルに引き出し、ノードにより小さなホットなワーキングセットを残すことができます。
移動するもの
コールドサブツリーを探します。これは、その下のすべてのリーフが非アクティブであるノードです(currentPeriod - leafPeriod >= 2、ステップ2の期間を使用)。コールドサブツリーが見つかったら、以下の2つの制限内で可能な限り最大のコールドサブツリーを取得します。
- 高さの上限。これにより、1つのサブツリーが大きくなりすぎるのを防ぎます。高さはリーフから数えられ、リーフは高さ1、リーフの直上のブランチは高さ2、といった具合で、その高さのサブツリーの下には最大16^(高さ-1)個のリーフがあります。
- 高さ2のフロア。これにより、単独のコールドリーフを移動することはありません。単一のリーフを移動すると、17バイトのスタブとアーカイブレコードのコストがかかり、内部ノードは節約されず、純損失となります。
BEFORE (PebbleDB内) AFTER
N (コールドサブツリーのルート) N -> 17バイトのスタブ --+
/ \ |
(ブランチ)(ブランチ) 内部ノード サブツリーは削除され |
/ \ / \ (削除済み) PebbleDBから消える v
リーフ リーフ リーフ リーフ (すべて非アクティブ) ノードアーカイブ (フラットファイル)
+------------------------+
| [リーフ][リーフ][リーフ] ... |
+------------------------+
保存するものと、読み戻し方
移動された各サブツリーについて、そのリーフのみをフラットファイルに書き込み、サブツリー全体を17バイトのポインタに置き換えます。
- PebbleDB内のスタブ、17バイト:
[0x00 マーカー | fileOffset:8 | size:8]。実際のトライノードの最初のバイトは0xc0以上なので、0x00がそれと間違われることはありません。オフセットとサイズは、ファイル内のこのサブツリーのレコードを括ります。 - アーカイブ、リーフのみ: リーフごとに1つのRLPレコード、
[pathToLeaf, leafValue]。内部ノードはなく、リーフとその相対パスのみです。内部ノードはPebbleDBから削除されます。 - 読み戻し: レコードをロードし、各
(path, value)を新しいミニトライに再挿入します。再構築されたサブツリーはオリジナルと同一であり、そのハッシュはスタブが期待するものと一致する必要があり、これは破損チェックとしても機能します。
コールドリーフへのアクセス:
スタブ(オフセット, サイズ) -> レコード読み取り -> メモリ内でサブツリー再構築 -> 使用
リーフのみの理由:愚直な代替案
愚直な移動方法は、すべてのコールドノードを内部ブランチを含め、そのままフラットファイルにコピーします。これはメインデータベースから最も多くのものを解放しますが、フラットファイルがその代償を払います。同じデータディレクトリで両方を測定しました(論理的な値のバイト数で、同じ方法でカウントされるように):
| 愚直な方法: すべてのコールドノード、完全な構造 | 我々の方法: コールドサブツリー、リーフのみ(キャップ3) | |
|---|---|---|
| フラットファイルに格納されるもの | サブツリー全体、内部ノードもすべて | リーフのみ、内部ノードはアクセス時に再構築 |
| 書き込まれたスタブ | 316.3 M | 239.6 M |
| トライは148.1 GBから縮小 | 32.7 GB (-115.5) | 58.7 GB (-89.4) |
| フラットファイル | 162.39 GB | 82.96 GB 生データ / 41.58 GB 圧縮済み |
| 純ディスク合計 | +46.93 GB (増加) | -6.43 GB 生データ / -47.81 GB 圧縮済み |
愚直なアプローチはメインデータベースからより多くを解放しますが(我々の-89 GBに対し-115 GBのトライ)、そのフラットファイルは162 GBと、解放された量よりも大きいため、総ディスク容量は約47 GB増加します。リーフのみを保存することで、フラットファイルを十分に小さく保ち、総ディスク容量を削減できます。内部ノードを削除し、アクセス時に再構築することが、このトリックのすべてです。
コールドサブツリーの検索
1回のストリーミングパスで、トライと期間がスタンプされたスナップショットを並行してウォークし、リーフからすべての非アクティブな応答をロールアップします。コールドサブツリーが完成し、フロアとキャップの範囲内にある場合、サブツリーを具体化し、リーフレコードを書き込み、スタブをステージングし、内部ノードを削除します。これらすべてを同じパスで行います。再構築されたハッシュのチェックは、何も削除される前に実行されるため、不一致があった場合は状態を破損させるのではなく、そのサブツリーの処理を中止します。
アーカイブの圧縮
フラットファイルはディスク上では生データですが、よく圧縮されます。約1 MBのチャンクに分割され、チャンクごとに1つのzstdフレームと小さなオフセットテーブルが追加されると、約半分に縮小されます。これにより、単一のサブツリーを再構築するためにそのチャンクのみを解凍することが可能になります。圧縮はパイプライン全体で最大の単一のレバーであるため、以下の結果では生データと圧縮済みアーカイブの両方を報告します。うまくいかなかった2つのこと:各リーフまたは各サブツリーを個別に圧縮すること(ブロックが小さすぎてzstdが何も見つけられないため)、およびサンプルレコードで学習された共有辞書(数ポイント数字が動く程度で、時には悪化させたため)。多くのサブツリーをまとめて圧縮する必要があります。
キャップの高さの選択
フロアが2であるということは、すべてのキャップが同じリーフを移動することを意味します。キャップは、それらのリーフがどのようにグループ化されるかだけを変更します。より高いキャップは、コールド領域を多くの小さなサブツリーではなく1つの大きなサブツリーにマージします。これにより、残される17バイトのスタブが減り、より多くの内部ノードが削除されるため、メインデータベースはより縮小されます。キャップを2から5までスイープし、フロアは2に固定しました。
| キャップの高さ | トライの削減 | アーカイブ(生データ) | アーカイブ(圧縮済み) | 純ディスク(生データ) | 純ディスク(圧縮済み) | 移動されたサブツリー | 最悪ケースの再構築(リーフ数) |
|---|---|---|---|---|---|---|---|
| 2 | -66.93 GB (-45.2%) | 63.35 GB | 31.39 GB | -3.58 GB (-1.4%) | -35.54 GB (-14.1%) | 295.1 M | 16 |
| 3 | -95.86 GB (-64.7%) | 82.96 GB | 41.58 GB | -12.90 GB (-5.1%) | -54.28 GB (-21.6%) | 239.6 M | 73 |
| 4 | -107.37 GB (-72.5%) | 89.19 GB | 44.79 GB | -18.18 GB (-7.2%) | -62.58 GB (-24.9%) | 158.4 M | 295 |
| 5 | -110.03 GB (-74.3%) | 89.98 GB | 45.16 GB | -20.05 GB (-8.0%) | -64.87 GB (-25.8%) | 116.4 M | 1118 |
2つのパーセンテージは異なるベースラインを使用しています。トライの削減はトライサイズ(ステップ1の148.1 GB)に対するもので、移動はトライノードのみを削除し、スナップショットはそのまま残します。純ディスクの列は、ディスク上の合計251.75 GBのフットプリントに対するものです。
より高いキャップは常にディスク容量をより多く節約しますが、その利益は急速に縮小し、各ステップは前回の約半分になります。一方、最悪ケースの再構築は逆方向に増加します。
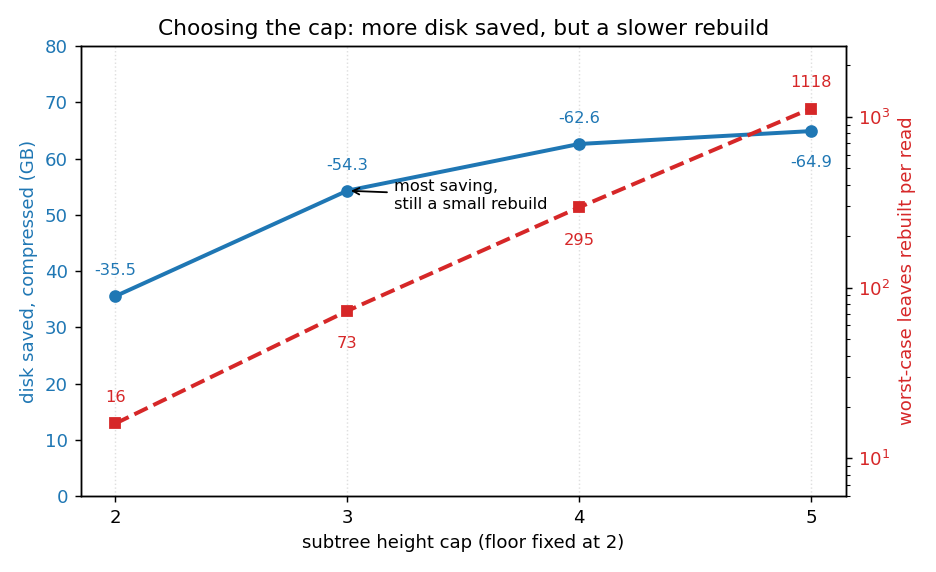
これがキャップを選択する際の実際のトレードオフです。より大きなキャップはディスクをさらに削減しますが、コールドステートに触れるすべてのアクセスはサブツリー全体を再構築し、より大きなサブツリーは再構築が遅くなります。キャップ2では最大16のリーフを再構築し、キャップ5では1000以上になります。したがって、最も深いキャップが必ずしもスイートスポットではありません。キャップ3が最適なバランスです。ディスク節約のほとんど(最も深いキャップでの可能な-64.87 GBのうち-54.28 GB)を確保しつつ、再構築を最大73リーフと小さく保ちます。キャップ4はさらに8 GBを節約しますが、再構築が約4倍大きくなり、キャップ5は1000以上のリーフの再構築に対してほとんど何も節約しません。
エンドツーエンドの要約
ステップ1 ベースライン ステップ2 期間注入 ステップ3 非アクティブな状態を移動
--------------- -------------------- ------------------------
トライ 148.1 GB ---> トライ 148.1 GB (同じ) -> トライ 約59 GB + 240 Mスタブ
スナップショット 101.4 GB ---> スナップショット 101.6 GB (+0.3) -> スナップショット 101.6 GB (同じ)
タイムスタンプなし すべてのリーフにその ノードアーカイブ 83 GB 生データ
最終使用期間がある (42 GB 圧縮済み)
| ステップ1 ベースライン | ステップ2 注入後 | ステップ3 移動後 (フロア2 / キャップ3、最適なバランス) | |
|---|---|---|---|
| トライノード | 1,895.4 M | 1,895.4 M | 788.0 M (-58%) |
| スナップショット | 101.38 GB | 約101.6 GB (+0.5%未満) | 約101.6 GB |
| 外部アーカイブ | - | - | 82.96 GB 生データ / 41.58 GB zstd |
| PebbleDB (物理、圧縮済み) | 251.75 GB | 251.75 GB | 155.89 GB (-95.9 GB) |
| ベースラインに対する純ディスク合計 | - | 約+0.3 GB (+0.1%) | -12.90 GB (-5.1%) 生データ / -54.28 GB (-21.6%) 圧縮済み |
ここから得られること:
- 移動により、コールドな内部ノードを削除し、コールドなリーフを再配置することで、ホットデータベースが縮小されます。フロア2 / キャップ3のルールでは、PebbleDBが95.9 GB減少し、リーフはより安価なストレージに格納できるフラットファイルに移動します。
- アーカイブを考慮しても、ディスク上の総容量は縮小します。生データで-12.90 GB、チャンク圧縮を使用すると-54.28 GB(約22%)です。その代償は、コールドステートへのまれなアクセス時に小さなサブツリーを再構築することであり、このキャップでは最大73リーフです。
- キャップの高さは、ディスクサイズと再構築コストの間のトレードオフです。より深いキャップはより多くのディスクを解放しますが、最悪ケースの再構築を大きくし、ディスクの利益は急速に縮小する一方で、再構築コストは上昇します。キャップ3が最適なバランスであり、キャップ4はより積極的(より多くのディスク、より大きな再構築)であり、キャップ5はほとんど価値がありません。
未解決の疑問
実際のワークロード下でのパフォーマンス。 上記のすべては静的なフットプリント測定です。測定されていないのは、コールドステートを変更する際のパフォーマンスコストです。コールドサブツリーへのすべてのヒットは再構築の代償を払います。リーフレコードを読み取り、メモリ内でサブツリーを再構築し、返す前にハッシュチェックを行います。これは浅いキャップでは安価であり、キャップ3では最大73リーフですが、キャップとともに増加し、キャップ4では約300リーフ、キャップ5では1000リーフを超えます。そして、コールドサブツリーへのすべてのアクセスで発生します。これが、より深いキャップがより多くのディスクを節約するにもかかわらず、自動的に優れているわけではない主な理由です。
したがって、フットプリントの勝者が自動的にワークロードの勝者ではありません。最も多くのディスクを節約する設計でも、一般的なアクセスパターンがコールドサブツリーに繰り返しアクセスし、再構築の代償を払い続ける場合、負ける可能性があります。まだ実行していない実験は、実際のメインネットブロックと、意図的にコールドステートにアクセスするいくつかの敵対的なパターンをリプレイすることです。圧縮はここで第2の層を追加します。圧縮されたチャンクへのヒットも、そのチャンクの解凍の代償を払うからです。したがって、この文書で提示された数値は、ストレージフットプリントの参照としてのみ機能し、パフォーマンスの参照としては機能すべきではありません。
1投稿 - 1参加者