原文
Why Homogenizing the Execution of the World-Computer Beats Scaling Through Fragmentation — conalloreilly (2026-05-12)
「1999年のスマートフォンでできなかったことは、イーサリアムブロックチェーンでも何もできない。」—Vitalik Buterin
ワールドコンピューター
ワールドコンピューターを構築したいだろうか、それとも、多数の壊れたNokiaに周回されたワールドスマートフォンを構築したいだろうか?後者の場合、Nokiaデバイスとスマートフォンの間の通信はEOAC(Ethereum Over Avian Carrier)として実装されているが、鳥が鳥インフルエンザにかかっているという注意書きが付いている。もし後者のケースがレイヤー2ベースのスケーリングのように聞こえるなら、あなたは現在のイーサリアムエコシステムを強く理解している。なぜ実際には、イーサリアムは同期的にコンポーザブル(composable)、セキュア(secure)、そして分散型(decentralized)を維持しながらスケーリングすることがこれほど困難だったのだろうか?
宇宙を計算する一本のスレッド
ブロックチェーンは実際には瞬時に分散型ではないことが判明している。それらは単に状態変更を提案するためのラウンドロビン選挙システムとして機能するため、どの瞬間においても1つのノードが制御し、1つのスレッドのみが実行されている。単一スレッドのスマートフォンを多次元のワールドコンピューターにスケーリングするにはどうすればよいだろうか?答えは、たとえ12秒ごとにプロセッサを切り替えたり、未知の闇から一部の計算をロールアップしたりしても、宇宙全体を1つのシーケンシャルスレッドで実行するわけではない、ということだ。結局のところ、チェーンはその最も弱いリンクと同じくらいしか強くない。
より良い解決策は、ワールドコンピューターの実行をネットワーク全体で均質化し、ワールドコンピューターの状態(そしておそらく履歴)のストレージをネットワーク全体で均質化することだろう。結局のところ、調整を均質化することこそが分散化のすべてであり、データストレージと状態実行は単なる調整の単位に過ぎない。データアベイラビリティサンプリングは、ストレージコミットメント(storage commitments)、イレイジャーコーディング(erasure coding)、および冗長性(redundancy)を使用して、データと状態のストレージをバリデーターセット(validator-set)全体に分散させることで、全員が自分でデータを保存する必要なく、誰かによってデータが保存されていることを証明し、状態の均質化問題を解決する。この準研究論文は実行のみを議論するため、ここでは(ステートレスな)前提を置かせてもらう。
ストレージコストは実行コストである
ストレージコストはブロックチェーンにおける計算コストに類似しており、両者のボトルネック間でバランスが取られているに過ぎない。例えば、イーサリアムの現在のワールドステート(world-state)モデルをステートレス(stateless)モデルと比較してみよう。ステートフル(現在の)モデルでは、すべてのノードが情報のすべてのバイトを保存し、これにはノードにとって定量化可能なストレージコストがかかる。また、ブロックの実行/検証にも、すべてのノードが負担する計算コスト(ガスとして定量化される)がかかる。一方、(根本的に)ステートレスなモデルでは、すべてのノードはワールドステートのトライ(trie)のルートのみを保存するかもしれない(より過激でないバージョンでは、ストレージトライなしでワールドステートを保存するだろう)。しかし、すべてのノードは依然として、すべてのブロックを実行/検証するための計算コストを負担する。ステートレスモデルでは、状態遷移を実行するノードは、まずトランザクション内で変更されるストレージスロット(storage-slots)の値を証明するマークルプルーフ(merkle-proof)をマークル検証(merkle-verify)する必要がある。
これは、ノードにとっての経済的コストが、ディスクへのデータ保存から実行中のプルーフ検証へと移行することを意味する。この意味で、ストレージコストと実行コストは同一である。すべてのストレージコストは、ノードのディスクにシフトされた実行コストに過ぎない。質量が宇宙における(非常に)遅いエネルギーであるのと同じように、ユニバースコンピューター(universe-computer)の質量は、計算エネルギーに相当する遅いストレージである。
上記のステートレスモデル、つまりストレージコストが完全に実行コストに移行すると仮定すれば、問題は根本的に単純化される。今や我々がすべきことは、実行スループット(execution throughput)をスケーリングすることだけであり、そうすればブロックチェーンのトリレンマ(trilemma)は解決され、イーサリアムの構築を手伝うために取った長いギャップイヤーの後、ようやく皆で大学に戻ることができる。やった!
シャーディングは理にかなっていたが、断片化はそうではない
さて、素晴らしい。では、ワールドコンピューターの実行をどのようにスケーリングすれば、宇宙全体だけでなく、宇宙の状態が依然として意味をなすことを示すマークルプルーフさえも収容できるだろうか?シャーディング(Sharding)は、イーサリアムの初期にEth-2.0の主要項目としてスケーリングソリューションとして登場した。しかし、シャーディングの興味深い点は、直感に反してブロックチェーンがすべきことと正反対のことをすることだ。つまり、チェーンをいくつかの(通常は2のべき乗の)ピースに分割する。それにもかかわらず、シャーディングには明白な利点がある。説明させてほしい。
ブロックチェーンは根本的にコンセンサスシステム(consensus systems)である。他者と協調したい場合、協調された取り組みの現在の状態(ワールドステート)と、その協調がどのように変化しうるかのパラメータ(状態遷移関数)について合意するだけでよい。問題は、ブロックチェーンが、ほとんどの場合この機能が使われないにもかかわらず、あらゆるユーザーが他のあらゆるユーザーと一度にやり取りできるという魔法のような特性のために、スケーリングのための膨大なマージンを犠牲にしていることだ。もしボブがUniswapでジェフコインしか取引しないなら、なぜ彼はOpenSeaで山男の肖像画しか買わないアリスにギャブコインを送る権利のために支払う必要があるのだろうか?
ボブやアリスのような多くのユーザーがいる場合、彼らのそれぞれのプラットフォームとのやり取りをメインチェーンから「シャード(shard)」し、信頼不要なブリッジ(言うは易く行うは難しだが)を設けて、もし彼らが山男の肖像画をジェフコインと交換する必要が生じた場合にメインチェーンに戻れるようにするのは、直感的に理にかなっている。これは、すべてを1つのスレッドで実行するよりもパラダイム的に優れているが、私は、新しい「シャードチェーン(shard-chain)」をいつ、どのように作成するかを実際に決定し管理する複雑さ、そしてシャード内/シャード間のセキュリティを管理する方法の複雑さのために、このアプローチは失敗すると主張したい。
このように、チェーンをシャーディングするというアイデアは、ロールアップ中心のロードマップに取って代わられた。これは、新しい信頼の前提(trust assumptions)を導入することでセキュリティモデルを実質的にシャード化するものだが、私の意見では、カジノ、ラザルス、あるいはそもそもイーサリアムを必要としないであろうアプリケーションに向かう需要に対応するためだけに、その価値は決してなかった。レイヤー2はイーサリアムにブロックチェーンのトリレンマの複数の側面を触れさせるが、率直に言って、それらの側面の一部は、イーサリアムをイデオロギー的に価値あるものにしているものと根本的に一致しないと主張できる。
委任型実行シャーディング(Delegated Execution Sharding, DES)
「私に十分大きなスナークと計算する場所を与えよ、そうすれば私はワールドコンピューターを証明してみせよう。」—アリストテレス
したがって、チェーンやセキュリティモデルをシャーディングするのではなく、実行(execution)をシャーディングすることでチェーンをスケーリングする方が、根本的により強力なパラダイム(paradigm)であるように思われる。これがどのように機能するかの一般的な説明を以下に示す。
この概念は、Lean ConsensusアーキテクチャのコンポーネントであるLean Ethereum Multi-Sigに触発されている。Lean-landの賢者たちは、量子耐性のあるXMSS(extended merkle signature scheme)署名を使用するビーコンチェーン(Beacon chain)の新しいバージョンをすでに設計している。我々凡人が量子コンピューティングの魔法について考えている間に、彼らは先を行っているのだ。「Multi-Sig」の「Sig」の部分は、バリデーター(validator)がXMSSで署名を作成する場所であり、「Multi」の部分は、スナーク(snarks)を使用して委員会(committee)全体でこれらの署名を集約し、BLS署名によるペアリングベースの集約(pairing-based aggregation)に似たものを実現する場所である。これらの委員会のスナークは、さらに多くのスナーク(スナークセプション)で再帰的に集約され、1つのコンセンサスブロック(consensus block)に含まれる。この本当に素晴らしい点は、ペアリングベースの集約と同じ効果を、暗号的にではなく計算的に達成していることだ。ただし、署名を集約する両方の方法は、ある種のコンセンサスの並列化に類似している。
このようにコンセンサスを並列化できるなら、EVMの実行でも同じことはできないだろうか?できる。そして、スナークは証明されるデータのサイズに応じて(実際には)増加しないため、追加のオーバーヘッドはほとんどない。ただし、同じ状態に触れないトランザクション(transaction)のみを効率的に並列化できるという注意点がある。しかし実際には、並列化の余地がないことはめったになく、BAL(Block-level Attestation Lists)の存在とその重要性がこれを証明している。これを機能させるには、BALで既に持っているものを拡張して、複数のスレッドでブロックを実行するだけでよい。しかし、バリデーターは有限のスレッドしか持たないため、ガスリミット(gas limit)を拡張し続けると、実行を別の「実行委員会(execution-committee)」に移すことができる。この委員会はトランザクションの独自のサブセットを実行するが、他の委員会のスレッドを信頼できないため、スナークを使用して、素朴な再実行なしに有効な実行を証明する。これにより、Lean Multi-Sigが署名委員会(signing committees)全体でアテステーション(attesting)を均質化するのとまったく同じ方法で、一連の実行委員会全体でブロックの実行を均質化できる。バリデーターセット全体に実行委員会を編成し、N個の委員会のスナークを再帰的に集約する「スーパー委員会(super-committees)」を編成し、最終的にブロック提案者(block-proposer)が計算する、すべてを証明する1つの最終的な聖杯スナークに到達するまでこれを行うと、通常のブロックを1つ実行する時間と、約Log(N) + 1個のスナークプルーフ(snark proofs)を計算する時間だけのオーバーヘッドで、膨大な量を実行できる。委員会の編成方法によっては、プルーフの検証に追加のオーバーヘッドがあることに注意してほしい。
委任型実行シャーディング(Delegated Execution Sharding, DES)は、利用可能なすべてのリソースを活用することでネットワークを幅優先でスケーリングすることを可能にし、リアルタイム検証(バリデーション)のボトルネックを対数的に、遡及検証(同期)時間を一定に保つ。これは、スループット(throughput)を深さ優先でしか増加させず、その過程で多くの望ましくないセキュリティ上の前提(security assumptions)とイデオロギー的な犠牲を導入するロールアップベースのスケーリングとは対照的である。
DESアーキテクチャの実践例
実用的なDESアーキテクチャは、大まかに言って3つの重要な特徴を持つ。
- ペイロード配信スキーム(Payload delivery scheme)
- デクサリーツリー(Dexary tree、委任型実行N項ツリー)
- 並列化エンジン(Parallelization engine)
ペイロード配信スキーム: ある点を超えてスケーリングするには、トランザクションが実行委員会が計算する「サブブロック(sub-blocks)」に組み込まれる方法を最適化する必要がある。問題は、トランザクションの純粋な量のためにメモリプール(mempool)が肥大化し、すべてのバリデーターがノード全体でメモリプール全体を複製することが非現実的になることだ。より良い解決策は、インクルージョンリスト(inclusion lists)を使用して、ネットワークのノードのメモリプール内のトランザクションの存在を集合的に投票し、その後、それらのトランザクションを委任された計算に必要なノードに指示することである。インクルージョンリスト内のトランザクションのメタデータ(metadata)は、トランザクションハッシュ(transaction hash)と、アクセスリスト(access lists)のような並列化エンジンにとって有用なデータである可能性がある。メタデータは、コンセンサスエンジン(consensus engine)がトランザクションをデクサリーツリーのノードに委任される「実行列(execution columns)」に分割することを可能にする。これは、あるスロット(slot)のデクサリーツリーの構造が確立されると、委員会が利用可能でなければならないトランザクションが明らかになり、ネットワーキング層が必要なデータの伝播を調整できることを意味する。ただし、どのノードもすべてのトランザクションを利用できる可能性は低く、ハッシュのみが公開されているため、委員会がどのトランザクションを実行するかを特定することは依然として困難であることに注意してほしい。興味深いことに、ネットワークがスケーリングするにつれて、メモリプールの可用性(mempool availability)の問題がデータアベイラビリティ問題に似てくるため、どのノードも保存できないほど大きな仮想メモリプールを作成するためにデータアベイラビリティサンプリングが使用される可能性は興味深いだろう。状態の取得自体に関しては、2つの方法がある。ユーザーは、前述のステートレスモデルのように自分の状態を追跡し、トランザクションにマークルプルーフを含めることができる。あるいは、データアベイラビリティサンプリングの何らかの形式を使用して、状態とストレージトライをすべてのノードに複製することなく、可用性を保証する方法でバリデーターセット全体に状態を分散させることができる。後者が望ましい理由は、現実には、外部アカウントによって変更される可能性がある場合、自分の状態の値を追跡することが非常に困難になる可能性があり、コモンズの悲劇(tragedy of the commons)が起こり、誰もその状態を追跡しなくなることで、公開契約が消滅する可能性が十分にあるためである。プライバシーもこれをほぼ不可能にする。
デクサリーツリー: 各スロット(slot)で、RANDAOを使用してバリデーターセット全体に実行を委任するツリー状の構造が計算される。これはデクサリーツリー(delegated execution N-ary tree)と呼ばれ、バリデーターを実行/集約委員会(execution/aggregation committees)に分割するために使用される。ツリーは、実行委員会がリーフノード(leaf nodes)として下部に配置され、集約委員会が有効な実行のプルーフ(proofs)をツリー全体で再帰的に上方に引き上げ、最終的なプルーフがルートノード(root node)に伝播されるまで構築される。この場合、ルートノードはそのスロットのプロポーザー(proposer)である。
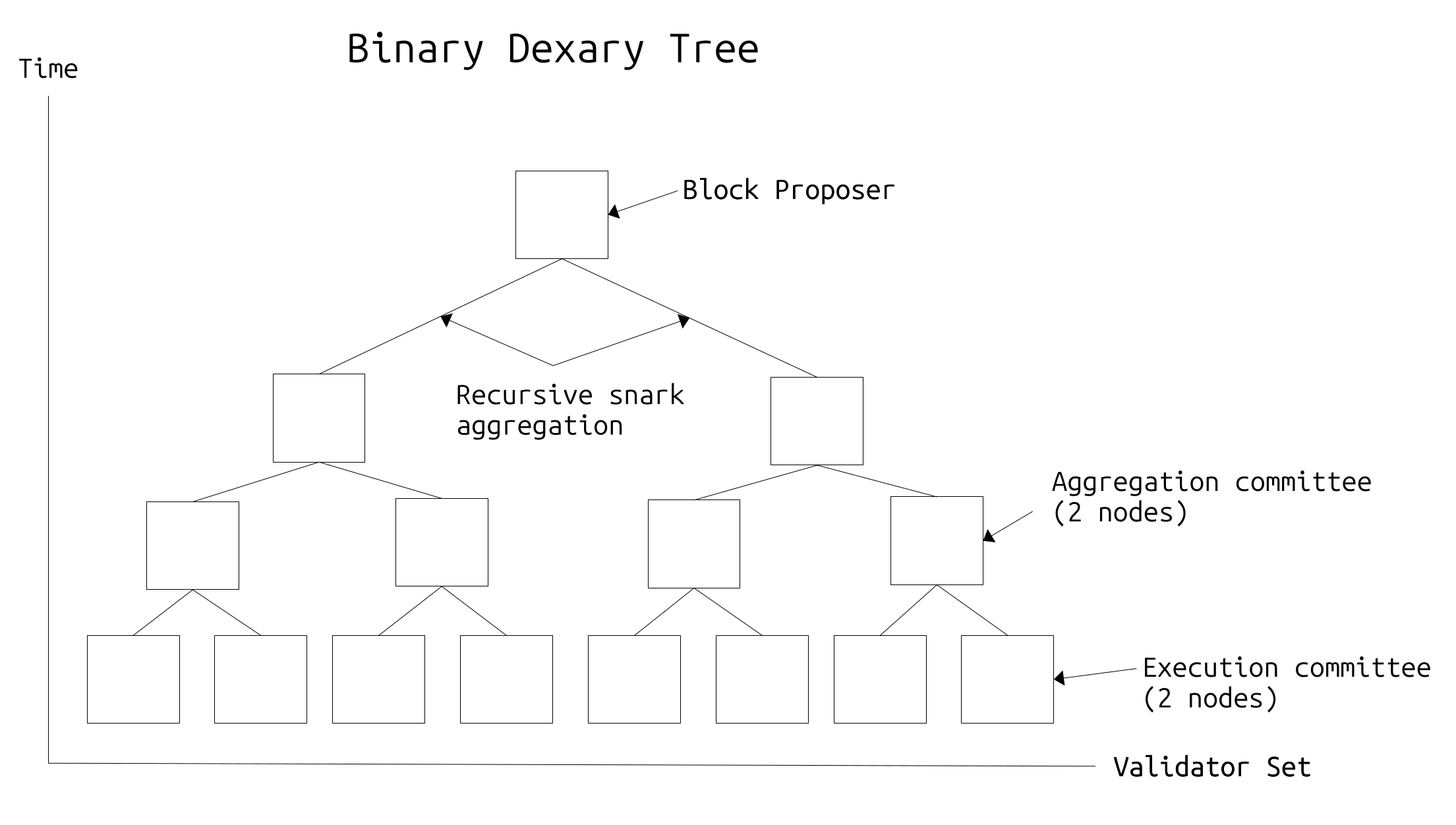
実行委員会は、実際のサブブロックを計算し、有効な実行のスナークプルーフを作成するN個のノードで構成される。N個のノードが冗長性(redundancy)を確保するために使用される。つまり、委員会内のすべてのノードがサブブロックの実行と証明に失敗し、それを集約委員会に送信する可能性は低い。したがって、冗長性は非同期またはその他の健全でないネットワーク状況の場合に回復力を保証する。集約委員会は、2つの実行委員会のサブブロックを検証し、スナーク集約する任務を負う。上記と同じ理由で、集約委員会にはN個のノードが存在する。階層的な証明構造は、膨大な量の実行が並列で発生できることを意味し、その実行の有効性を証明するためのボトルネックは、バリデーターの数に対して対数的に過ぎない。つまり、おおよそ以下のようになる。
execution + aggregation time = t + b + vN×LogN(c) + p×LogN(c)
ここで、 t = 1つのサブブロックを実行する時間 b = 1つのサブブロックを証明する時間 v = 1つのスナークプルーフを検証する時間 c = バリデーターの数 p = 1つの再帰的なスナークプルーフを計算する時間
実際には、ツリーはすべての委員会にN個のノードがあり、すべての委員会がツリー内のN個の委員会の新しいブランチであるように構築されているため、ツリーは等比数列のように構築されるだろう。
1 + N×N¹+ N×N² …
これは合計がバリデーターの数より大きくなるまで続き、その時点でバリデーターの数から最後から2番目の合計を引いたものをNで割ったものが実行委員会の数となる。
ネットワーキングのボトルネックは比較的小さく、実際にはかなり最適化されていることに注意してほしい。なぜなら、すべてのノードは自分がどの委員会に属しているかを知っており、したがってどの実行/集約委員会と通信すべきかを知っているからだ。実行委員会がサブブロックのzk-snarkプルーフを計算する場合、ボトルネックはさらに小さくすることができる。つまり、それらのトランザクションの正確な詳細を明らかにすることなく、サブブロックを計算するために有効なトランザクションセットが存在したことを証明するのだ。メモリプールの強制的なインクルージョン(inclusion)と難読化(obfuscation)も、有害なMEV(最大抽出可能価値)を通じて価値を抽出することをはるかに困難にする。
興味深い点として、デクサリーツリーは、ツリー全体の構造が明らかにされない方法でスロット内で計算できるため、個々のバリデーターはツリー内での自身の位置のみを知る。これは、プライバシーを維持しながら、あらゆるDOS攻撃ベクトルを回避するのに役立つ。上記で述べたように、有効な実行のzk-snarkプルーフはサブブロックの有効性を証明するために使用できるため、ツリー内のどのノードも、またはチェーンの事後アクティブなバリデーターも、正確にどのトランザクションが発生したかを判断することは不可能である。本質的に、デクサリーツリーが達成するのは、その実行がバリデーターの数に応じてスケーリングするEVMである。現在のモデルでは、どのノードもワールドコンピューターの全状態を保存し、任意のブロックを再実行できる必要があるため、実行をスケーリングできる最大値は、個々のノードが耐えられる範囲である。これを分散化計算可能性限界(decentralization computability limit, DCL)と呼ぼう。現在のEVMのスループットは正確に1 DCLだが、デクサリーツリーを使用すると、並列処理の最適ケースで、上記の等比数列の最後から2番目のステップでの合計を引いたc / NのDCL数にまでスケーリングできる。
No. of DCLs (executing validators) = c / N - (N×N¹+ N×N² …)
等比数列は、集約委員会のメンバーが占めるバリデーター空間である。
これは、シーケンシャル実行(sequential execution)に関する問題の根本的な認識につながる。各バリデーターは、自身のステーク(stake)の規模に関係なく、チェーンの実行に同じリソースを貢献する。しかし実際には、32 ETHではなく64 ETHを貢献できるバリデーターは、ネットワークに追加のコンピューターを1台貢献できると仮定しても安全だろう。これは根本的に是正されるべき不均衡である。また、ステートレス性(statelessness)と簡潔な証明(succinct proving)がチェーンの検証を容易にし、読み取りと同期の面での分散化レベルを高めることも注目に値する。しかし、さらに大きな効果は、チェーンのバリデーションに参加するために必要なリソースが、貢献されたステークの量に応じてスケーリングすることである。これにより、ステーキング運用をスケーリングすることが信じられないほど困難になり、リキッドステーキングがほとんど実現不可能になる一方で、ソロステーカー(solo-stakers)のハードウェア要件は最小限に抑えられる。32 ETHのソロステーカーがデスクトップハードウェアでバリデーターを実行する方が、トム・リーやブラックロックがステーキングの資格を得るために数十万台のデバイスを購入し、ソロステーカーと同じ利回りを得るよりも簡単である。しかし、これはプルーフ・オブ・ワーク(proof-of-work)におけるASIC軍拡競争とは根本的に異なる。なぜなら、追加のハードウェアはコンセンサスに対する追加の制御も、追加の収益性マージンも提供せず、実際にはネットワークスループットに貢献するからだ。したがって、デクサリーツリーがもたらす可能性のあるわずかなオーバーヘッドは、追加のオーバーヘッドの大部分が裕福なステーカーによって感じられるという事実によって相殺される。これは、ノード要件の増加がステーカー/バリデーター/ユーザーのロングテール(long tail)に最も大きな打撃を与える現在のモデルにおける拡張的なハードウェア要件ポリシーとは対照的である。私は、前者が原則として根本的によりサイファーパンク(Cypherpunk)であると主張したい。なぜなら、個々の防御者は、組織化された攻撃者に対してより強力な防御(したがって、コンセンサス攻撃中の優位性)を持つからである。
並列化エンジン: デクサリーツリーが構築され、実行委員会がメモリプールデータを受け取ったら、状態上のトランザクションを並列で最適に実行するためのアルゴリズムが利用可能でなければならない。また、集約委員会は、実行委員会全体の状態変更を集約する手段を持っていなければならない。
基本的なレベルで並列処理を達成する直感的な方法は、各実行委員会に、他のどのバッチのトランザクションとも同じ状態に触れないトランザクションのバッチを与える単純なアルゴリズムを作成することだろう。この問題は、実行列をクロス列依存性がないようにシャッフルすることは決してできないことだ。このシャッフルと最適化はすべて、インクルージョンリストとデクサリーツリーが構築される際にコンセンサス層で処理されることに注意してほしい。より良い解決策は、上記のメソッドを修正し、十分な並列処理と最小限の列間状態衝突の両方があるように列をシャッフルすることで実行を最適化する方法がある場合、解決する必要がある交差する列間衝突のオーバーヘッドを最適化された並列処理と引き換えにするという追加のケースを設けることである。実際には、列間衝突はより高い層で解決する必要があるだろう。そのためのスキームは、あるトランザクションが別の実行列の他のトランザクションのバッチと同じ状態に触れる場合、交差点までソース委員会によって部分的な状態変更としてのみ実行されなければならず、実行は、実行列で衝突する両方の状態変更を最初に受け取る集約委員会によって完了される可能性があるというルールを含むかもしれない。デクサリーツリーのどのレベルにおいても、唯一交差する状態変更は既知の交差点であるため、それらは安全に、伝播された状態変更を集約するだけで、再帰的に集約された状態を得ることができる。より高い層で交差点を解決する代わりに、実行委員会自身がツリーの基部で直接解決できるというアイデアも興味深い。これは、参加者が重複する委員会を作成することで行うことができ、したがって交差点が発生する位置での状態変更も重複する。これは追加のネットワーキングオーバーヘッドを伴うアムダールの法則(Amdhel’s law)になるが、この状態変更のリアルタイムでの結合がどれほど優れているかは定かではない。
上記の場合、アムダールの法則の猛威は部分的なトランザクション実行によってある程度最小化できるが、それは単にさらなるオーバーヘッドを追加する非常に厄介なプロセスである。しかし、ここでBLSの素晴らしい世界に少し戻って観察してみよう。BLS署名が集約できる理由は、暗号学的ペアリング(cryptographic pairing)と呼ばれる奇妙なブードゥーマジックによるものだ。ペアリングの非常に素晴らしい特性はこれである。
b(m, k) + b(n, k) = b(m + n, k)
これは本当に素晴らしい。なぜなら、同じデータを署名する2つの署名を別々に検証する代わりに、両方をまとめて加算するだけで、結果の署名が有効であるのは両方の署名が実際にデータに署名した場合のみだとわかるからだ。私がこれを持ち出したのは、BLS集約を模倣したXMSSスナーク集約が委任型実行シャーディングのインスピレーションであったにもかかわらず、一周回ってBLSペアリングベース集約の特性が並列化に非常に役立つことに気づくことができるからだ。その理由は以下の通りだ。
この方程式が、単なる署名とデータではなく、EVMの状態s、トランザクション入力t1とt2、そして状態遷移関数phiを表していると想像してみてほしい。
**Φ**(t1, s) + **Φ**(t2, s) = **Φ**(t1 + t2, s)
これはBLS集約に類似しており、この方程式が真であることの意味は、無限の並列化が可能になるということだろう。なぜなら、同じ状態に触れるトランザクションを、バリデーターセット全体に実行を委任できるサブセットに常に分割できるからだ。これは、コンセンサス層でのシャッフルが一切不要になり、状態と交差する相互作用があったとしても、数学自体が最終的に状態変更を結合することを可能にするため、解決する必要のある列間の交差が一切なくなることを意味する。さて、あなたが何を考えているかはわかる。
「お前はどうかしているのか、この狂人め?ペアリングの特性を持つ双線形写像ベクトル乗算に過ぎない暗号操作が、どうにかしてチューリング完全(Turing-complete)であるかのように装うことはできないぞ。」—おそらくあなた
最良の問題とは解決不可能なものであり、最良の解決策とは意味をなさないものである。明らかに、私が説明している「チューリング完全な双線形写像(Turing-complete bilinear mappings)」というアイデアは、実際には数学的に誤りであることを指摘しておきたい。しかし、それは興味深い思考実験である。この種の計算のアイデアが修正された形で存在することは興味深い。つまり、完全準同型暗号(fully homomorphic encryption)スキームは、暗号化されたデータに対して計算を実行するために、この正確な特性を使用する。
e(a) + e(b) = e(a + b)
この場合、暗号化された入力aとbの合計は、aとbの暗号化された合計に等しい。ここでの計算は加算だが、アイデアは汎用回路(general-purpose circuits)上で計算することである。我々が本当に必要としているのは、暗号化関数が状態遷移関数になり、加算が状態変更を追加する連結操作(concatenation operation)になることだ。そうすると、我々が必要とする特性を「チューリング完全な準同型写像(Turing-complete homomorphism)」と表現するのがより適切かもしれない。私はそのようなスキームを知らず、それは純粋に想像上の思考実験のままだ。しかし、もし理想主義的なインターネットの魔法使いが宇宙のための魔法の計算基盤を発明できるのなら、ペアリングの特性を持つ魔法の準同型計算も可能かもしれない。結局のところ、我々が皆探しているものはただ一つなのだ。
「何に悩んでいるのだ、山男よ、何を探しているのだ?」
「ワールドコンピューターを記述するただ一つの式を。」
塵が晴れ、戦いが終わった時、ワールドコンピューターは我々全員よりも長く生き残るだろう。
1 post - 1 participant